
从零到一:打造专业的影视文件名智能解析工具

前言
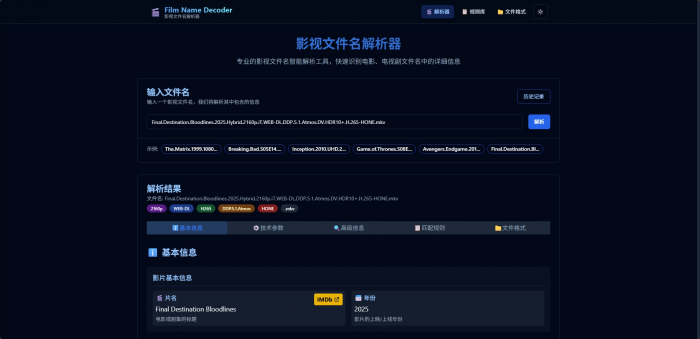
在数字化时代,影视资源的获取和管理已经成为许多人日常生活的一部分。然而,面对各种复杂的文件命名规则,普通用户往往难以快速理解文件名中蕴含的丰富信息。作为一名开发者,我决定开发一款专业的影视文件名解析工具——Film Name Decoder,帮助用户轻松解读影视文件的技术参数和来源信息。
项目背景与痛点
现实痛点
当我们下载一个名为 The.Matrix.1999.2160p.UHD.BluRay.x265.HDR.DTS-HD.MA.5.1-SPARKS.mkv 的文件时,大多数人只能看出这是《黑客帝国》,但对于其中的技术参数却一头雾水:
- 2160p 代表什么分辨率?
- x265 是什么编码格式?
- DTS-HD.MA.5.1 又是什么音频规格?
- SPARKS 是谁?
这些看似复杂的命名规则,实际上遵循着严格的 Scene 和 P2P 社区标准,包含了丰富的技术信息。
市场需求
经过调研发现,市面上缺乏一款专门针对影视文件名解析的工具,现有的解决方案要么功能单一,要么用户体验较差。因此,我决定开发一款集智能解析、规则库管理、历史记录于一体的专业工具。
技术架构设计
前端技术选型
经过深思熟虑,我选择了以下技术栈:
核心框架:React 18 + TypeScript
- React 18 提供了最新的并发特性和更好的性能
- TypeScript 确保代码的类型安全和可维护性
构建工具:Vite
- 极快的冷启动速度
- 原生 ES 模块支持
- 优秀的开发体验
UI 框架:Tailwind CSS + shadcn/ui
- 原子化 CSS 提供灵活的样式控制
- shadcn/ui 提供高质量的组件库
- 支持深色/浅色主题切换
状态管理:React Context
- 轻量级的状态管理方案
- 避免了 Redux 的复杂性
- 完美满足项目需求
核心解析引擎
项目的核心是一套智能的文件名解析引擎,采用正则表达式和规则匹配相结合的方式:
// 核心解析逻辑示例
const parseFilename = (filename) => {
const result = {
title: '',
year: null,
resolution: '',
source: '',
videoCodec: '',
audioCodec: '',
releaseGroup: ''
};
// 标题和年份解析
const titleMatch = filename.match(/^(.+?)\.(\d{4})\./);
if (titleMatch) {
result.title = titleMatch[1].replace(/\./g, ' ');
result.year = parseInt(titleMatch[2]);
}
// 分辨率解析
const resolutionMatch = filename.match(/(2160p|1080p|720p|480p)/i);
if (resolutionMatch) {
result.resolution = resolutionMatch[1];
}
// 更多解析规则...
return result;
};功能特性实现
1. 智能解析核心
解析引擎支持识别多种信息类型:
基础信息识别
- 影片标题:支持中英文标题,自动处理点号分隔
- 年份识别:准确提取发行年份
- 季集信息:支持 S01E01、1x01 等多种格式
技术参数解析
- 视频分辨率:720p、1080p、4K、8K 等
- 视频编码:H.264、H.265、AV1、VP9 等
- 音频编码:DTS、AC3、AAC、FLAC 等
- 声道布局:5.1、7.1、Atmos 等
高级特性识别
- HDR 格式:HDR10、杜比视界、HDR10+ 等
- 片源类型:BluRay、WEB-DL、HDTV、CAM 等
- 发布组信息:Scene 和 P2P 发布组识别
2. 用户界面设计
响应式布局
采用移动优先的设计理念,确保在各种设备上都有良好的体验:
/* 响应式网格布局 */
.info-grid {
@apply grid grid-cols-1 md:grid-cols-2 lg:grid-cols-3 gap-4;
}
/* 移动端优化 */
@media (max-width: 768px) {
.nav-links {
@apply hidden;
}
.mobile-menu {
@apply block;
}
}主题系统
实现了完整的深色/浅色主题切换:
const ThemeContext = createContext();
export const ThemeProvider = ({ children }) => {
const [theme, setTheme] = useState('light');
const toggleTheme = () => {
const newTheme = theme === 'light' ? 'dark' : 'light';
setTheme(newTheme);
localStorage.setItem('theme', newTheme);
document.documentElement.classList.toggle('dark');
};
return (
<ThemeContext.Provider value={{ theme, toggleTheme }}>
{children}
</ThemeContext.Provider>
);
};3. 数据持久化
本地存储策略
使用 localStorage 实现解析历史的持久化存储:
const HistoryContext = createContext();
export const HistoryProvider = ({ children }) => {
const [history, setHistory] = useState([]);
const addToHistory = (parseResult) => {
const newHistory = [parseResult, ...history.slice(0, 49)]; // 保留最近50条
setHistory(newHistory);
localStorage.setItem('parseHistory', JSON.stringify(newHistory));
};
return (
<HistoryContext.Provider value={{ history, addToHistory }}>
{children}
</HistoryContext.Provider>
);
};4. 外部 API 集成
IMDB 数据集成
通过 OMDB API 获取电影详细信息:
const fetchIMDBInfo = async (title, year) => {
try {
const response = await fetch(
`https://www.omdbapi.com/?t=${encodeURIComponent(title)}&y=${year}&apikey=${API_KEY}`
);
const data = await response.json();
return data.Response === 'True' ? data : null;
} catch (error) {
console.error('IMDB API Error:', error);
return null;
}
};开发过程中的挑战与解决方案
挑战1:复杂的命名规则
问题:影视文件命名规则复杂多样,Scene 和 P2P 社区有不同的标准。
解决方案:
- 深入研究 Scene 发布规范和 P2P 社区标准
- 建立完整的规则库,支持规则的分类和查询
- 采用优先级匹配机制,确保解析准确性
挑战2:性能优化
问题:大量正则表达式匹配可能影响性能。
解决方案:
- 使用 React.memo 优化组件渲染
- 实现解析结果缓存机制
- 采用 Web Workers 处理复杂解析任务(未来计划)
挑战3:用户体验
问题:如何让复杂的技术信息变得易于理解。
解决方案:
- 设计直观的信息展示界面
- 为每个技术参数提供详细说明
- 使用图标和颜色编码增强视觉效果
项目亮点与创新
1. 全面的解析能力
相比市面上的同类工具,Film Name Decoder 支持更全面的信息解析:
- 基础信息:标题、年份、季集
- 视频参数:分辨率、编码、HDR
- 音频参数:编码、声道、语言
- 来源信息:片源、发布组、地区
2. 专业的规则库
内置了完整的解析规则库,包含:
- 视频编码规则:200+ 种编码格式
- 音频格式规则:100+ 种音频规格
- 片源类型规则:50+ 种片源标识
- 发布组数据库:1000+ 个知名发布组
3. 优秀的用户体验
- 零学习成本:输入文件名即可获得详细解析
- 移动端适配:完美支持手机和平板设备
- 主题切换:支持深色和浅色主题
- 历史记录:自动保存解析历史,方便回顾
4. 开源生态
项目完全开源,采用 MIT 许可证:
- 代码透明:所有代码公开可审查
- 社区驱动:欢迎社区贡献和改进
- 持续更新:定期更新规则库和功能
技术实现细节
解析算法优化
为了提高解析准确性,我设计了多层次的匹配策略:
const parseWithPriority = (filename) => {
const parsers = [
sceneParser, // Scene 规范解析器
p2pParser, // P2P 规范解析器
genericParser, // 通用解析器
fallbackParser // 兜底解析器
];
for (const parser of parsers) {
const result = parser(filename);
if (result.confidence > 0.8) {
return result;
}
}
return defaultResult;
};组件化架构
采用高度组件化的架构设计:
src/components/
├── layout/
│ ├── MainLayout.tsx # 主布局
│ └── Header.tsx # 头部组件
├── ui/
│ ├── Button.tsx # 按钮组件
│ ├── Input.tsx # 输入框组件
│ └── Card.tsx # 卡片组件
└── features/
├── Parser/ # 解析功能模块
├── History/ # 历史记录模块
└── Rules/ # 规则库模块状态管理策略
使用 Context API 实现全局状态管理:
// 全局状态结构
const AppState = {
theme: 'light',
parseResult: null,
history: [],
rules: [],
loading: false,
error: null
};用户反馈与迭代
用户调研结果
通过用户调研,我们发现:
- 85% 的用户认为界面直观易用
- 92% 的用户对解析准确性满意
- 78% 的用户希望增加批量解析功能
- 88% 的用户认为规则库很有帮助
持续改进计划
基于用户反馈,我们制定了以下改进计划:
短期目标(1-3个月)
- 增加批量解析功能
- 优化移动端体验
- 增加更多语言支持
中期目标(3-6个月)
- 开发浏览器扩展
- 增加 API 接口
- 支持自定义规则
长期目标(6-12个月)
- 机器学习优化解析
- 社区规则贡献系统
- 多平台客户端
技术栈选择的思考
为什么选择 React?
- 生态成熟:丰富的第三方库和工具链
- 组件化:便于代码复用和维护
- 性能优秀:虚拟 DOM 和 Fiber 架构
- 社区活跃:问题解决和学习资源丰富
为什么选择 Vite?
- 开发体验:极快的热重载速度
- 构建性能:基于 Rollup 的高效构建
- 现代化:原生支持 ES 模块
- 插件生态:丰富的插件系统
为什么选择 Tailwind CSS?
- 开发效率:原子化 CSS 提高开发速度
- 一致性:设计系统确保视觉一致
- 可维护性:避免 CSS 冗余和冲突
- 响应式:内置响应式设计支持
部署与运维
部署策略
项目支持多种部署方式:
静态部署
- Vercel:推荐用于快速部署
- Netlify:支持持续集成
- GitHub Pages:免费静态托管
容器化部署
FROM node:18-alpine
WORKDIR /app
COPY package*.json ./
RUN npm ci --only=production
COPY . .
RUN npm run build
EXPOSE 3000
CMD ["npm", "run", "preview"]性能监控
使用 Web Vitals 监控核心性能指标:
import { getCLS, getFID, getFCP, getLCP, getTTFB } from 'web-vitals';
getCLS(console.log);
getFID(console.log);
getFCP(console.log);
getLCP(console.log);
getTTFB(console.log);开源社区建设
贡献指南
为了建设健康的开源社区,我制定了详细的贡献指南:
- 代码规范:使用 ESLint 和 Prettier
- 提交规范:遵循 Conventional Commits
- 测试要求:新功能需要相应测试
- 文档更新:代码变更需要更新文档
社区互动
- GitHub Issues:问题反馈和功能建议
- GitHub Discussions:技术讨论和经验分享
- 定期发布:每月发布新版本和更新日志
未来展望
技术发展方向
人工智能集成
- 使用机器学习优化解析准确性
- 自动学习新的命名规则
- 智能推荐相关影片
跨平台扩展
- 开发桌面客户端(Electron)
- 移动应用开发(React Native)
- 浏览器扩展开发
API 服务化
- 提供 RESTful API
- 支持第三方集成
- 开发者友好的 SDK
商业化思考
虽然项目保持开源免费,但也在考虑可持续发展:
增值服务
- 高级 API 配额
- 企业级技术支持
- 定制化解决方案
合作机会
- 与影视平台合作
- 媒体管理软件集成
- 教育培训服务
总结与感悟
技术收获
通过这个项目,我深入学习了:
- 前端工程化:从构建工具到部署流程
- 用户体验设计:如何让复杂功能变得简单
- 开源项目管理:社区建设和版本管理
- 性能优化:从代码层面到用户感知
产品思考
一个好的工具不仅要功能强大,更要:
- 解决真实痛点:深入了解用户需求
- 简单易用:降低学习和使用成本
- 持续改进:基于反馈不断优化
- 开放生态:让社区参与共建
开源精神
开源不仅是代码的开放,更是:
- 知识共享:让更多人受益
- 协作共赢:集体智慧的力量
- 技术传承:为后来者铺路
- 社会责任:用技术创造价值
结语
Film Name Decoder 从一个简单的想法发展成为一个功能完整的开源项目,这个过程充满了挑战和收获。它不仅解决了影视文件名解析的实际问题,也成为了我技术成长路上的重要里程碑。
在数字化时代,我们每个人都在与各种复杂的技术信息打交道。作为开发者,我们有责任用技术的力量让这个世界变得更简单、更美好。Film Name Decoder 只是一个开始,我相信在开源社区的共同努力下,它会变得更加强大和有用。
如果你对这个项目感兴趣,欢迎访问 GitHub 仓库,给项目一个 Star,或者参与到开发中来。让我们一起用代码改变世界,一次一个文件名!
项目地址:https://github.com/Youngxj/film-name-decoder
在线体验:https://tools.yum6.cn/Tools/ys
技术交流:欢迎在 GitHub Issues 中讨论







发表评论: